Kubernetes 架构 Overview
最近正在复习准备考试,于是一边复习一遍写成博客,印证自己所学。
Kubernetes架构
从高层看,kubernetes是由如下东西组成的:
- 一个或多个master node
- 一个或多个worker node
- 一个分布式的key-value存储,比如
etcd
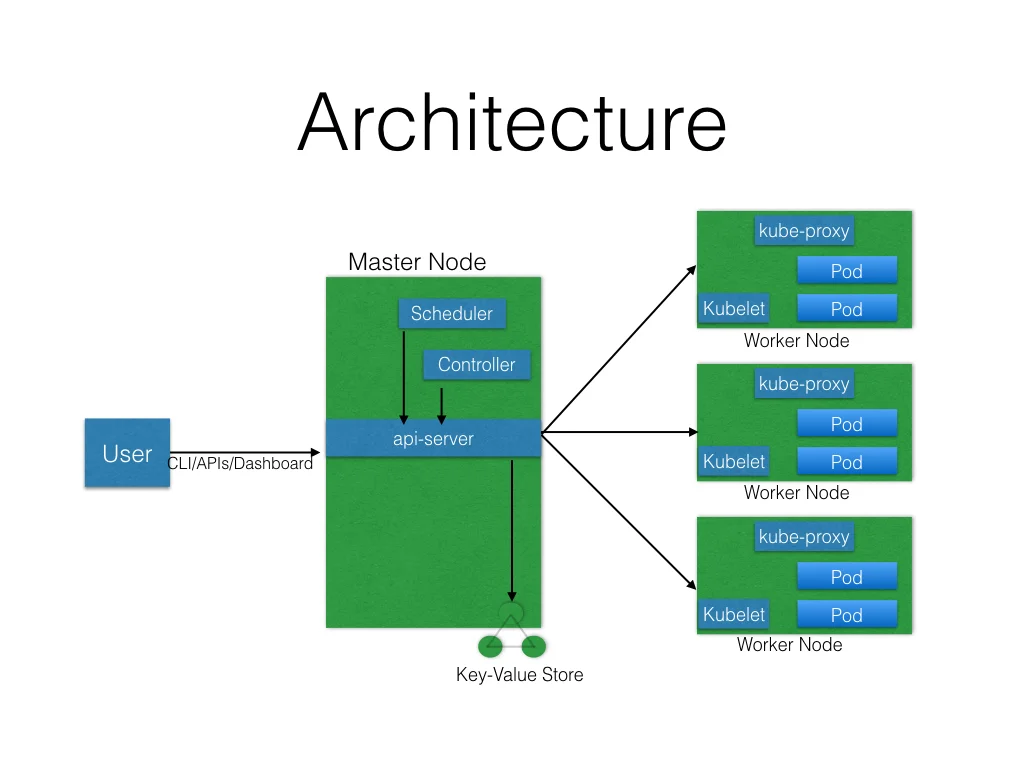
Master Node
Master node 是集群管理者,我们发出的所有请求都是到master node的api server上。
一个集群可以有多个master node做HA,当有多个master node的时候,只有一个会提供服务,剩下的都是follower。
集群的状态一般存储在etcd里面,所有的master node都会连接到etcd。etcd是一个分布式k-v存储。etcd可以是master内部的,也可以是外部的。
Master node的组件
master node一般都有如下组件:
API Server
所有的操作都是通过 API Server 去完成的。每个用户/操作者通过发送REST请求到api server,然后api server先验证然后执行这些操作。在执行完之后把集群的状态存到etcd里面。
Scheduler
顾名思义,Scheduler的作用是调度,Scheduler拥有所有worker node的资源使用情况,同时也知道用户设置的资源需求,比如说一个 disk=ssd的label。在调度之前,scheduler还会考虑到service requirements,data locality,affinity,anti-affinity等。scheduler负责的是service和pod的调度。
Controller Manager
简单来说,Controller Manager是负责启动和关闭pod的。Controller Manager的任务是让集群维持在期望的状态上。Controller Manager知道每个Pod的状态应该是什么样,然后会不断检测是否有不达标的pod。
Worker Node
Worker Node就是一个被master node控制的机器,Pod一般都是调度到worker node里面的。Worker node会有一些可以运行以及连接容器的工具。Pod是kubernetes里面的调度单元,是一个或多个容器组成的通常一起调度的逻辑上的集合。
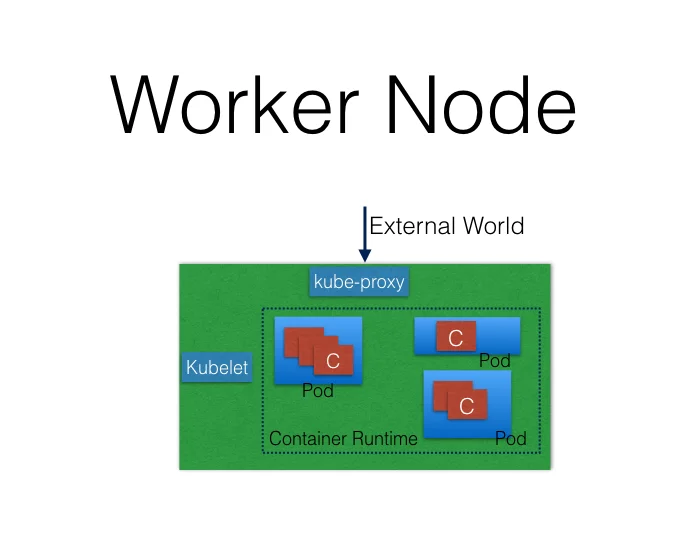
Worker Node组件
一个worker node一般会有以下组件:
Contrainer Runtime
不用多说了,运行容器必备的,默认用的是Docker
kubelet
kubelet是在每个worker node上都会运行的,用来和master node通信的。kubelet从master接收pod的定义,然后启动里面的容器,并监控容器是否一直正常运行。
kube-proxy
kube-proxy简单来说,就是对外提供代理服务的。换句话说,没有kube-proxy,我们要访问其中的application,就得直接访问到worker node上,这显然是不合理的。我们可以通过kube-proxy来做load balancer等。以前版本的Service也借助了kube-proxy。
用etcd来管理状态
在kubernetes里面,都是用的etcd来管理所有的状态。除了集群的状态之外,还会用来存放一些信息,比如configmap,secret。
网络需求
为了启动一个全功能的kubernetes集群,我们需要先确认以下信息:
- 每个Pod有唯一一个独立的IP
- 每个Pod里面的容器可以互相沟通
- Pod之间可以互相沟通
- 通过设置,在Pod里面的application可以被外部访问到
这些问题都是需要在部署之前被解决的。
我们一个个看:
给每个Pod分配一个独立的IP
在kubernetes里面,每个Pod都要有一个独立的IP。一般容器网络有两种规格:
- Container Network Model (CNM)
- Container Network Interface (CNI)
Kubernetes用CNI来给Pod分配IP
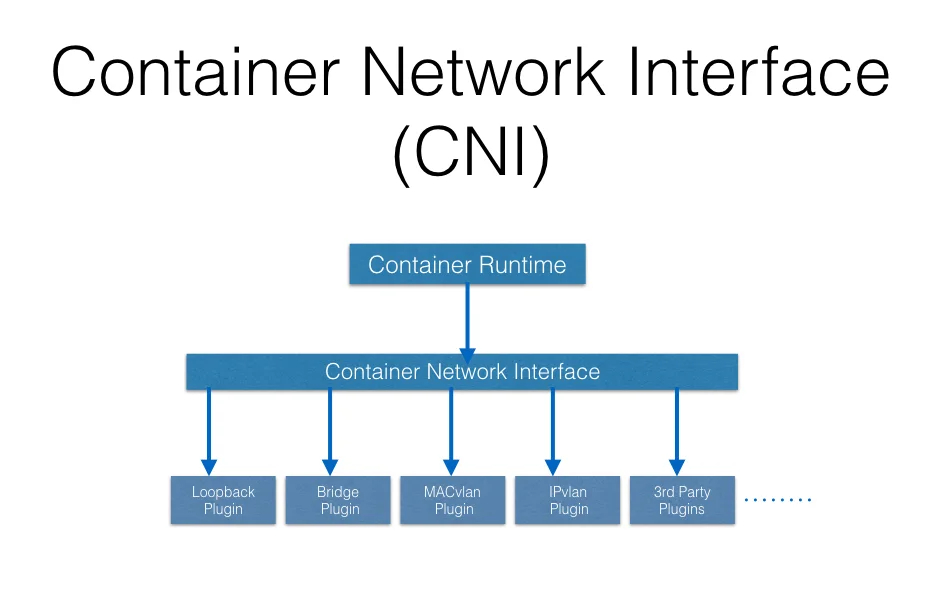
简单来说,容器运行时向CNI申请IP,然后CNI通过其下面指定的plugin来获取到IP,并且返回给容器运行时。
容器之间交流
一般基于底层操作系统的帮助,所有的容器运行时都会给每个容器创建一个独立的隔离的网络整体。在Linux上,这个整体被称为Network Namespace,这些Network Namespace可以在容器之间共享。
在一个Pod里面,容器共享Network Namespace,所以所有在同一个Pod里面的容器可以通过localhost来互相访问。
跨Node的Pod之间访问
在一个集群的环境下,每个Pod可以被调度到任何一个Node上,我们需要让在不同机器上的Pod也可以相互通信,并且任何Node都可以访问到任何Pod。Kubernetes设定了一个条件:不能有任何的NAT转换,我们可以通过以下方式来达成:
- 可路由(Routable)的Pod和Node,通过底层的服务,比如GCE。
- 通过一些软件定义的网络(Software Defined Networking),比如flannel,weave,calico等
更多的信息可以看看kubernetes的官方文档。
外网和集群之间的访问
我们可以通过kube-proxy来暴露我们的service,然后就能从外面访问到我们集群里面的应用了。