Kubernetes Building Blocks
Kubernetes中有很多积木(Building Blocks),比如object model,pod,rs,deployment,namespace之类,这些都是kubernetes中很重要的东西。
Kubernetes Object Model
kubernetes有一个非常完善的对象模型,kubernetes集群可以通过这个对象模型来表现出不同的持久化的整体,比如:
- 我们是在哪个node上运行哪个容器化的应用程序?
- 应用程序资源消耗
- 应用程序不同的策略
对于每个对象,我们用spec这个field声明我们期望的状态,随后kubernetes会通过status这个field记录对象实际的状态并加以管理。随后,kubernetes的controller manager会想办法让这个对象实际的状态和我们声明期望的状态相同。
kubernetes中的例子比如:Pods,Deployments,ReplicaSets之类。
如果我们要创建一个对象,我们需要把spec这个field提供给API Server,这个field会描述我们期望的状态以及一些基础的信息,比如名称。创建对象的API请求必须有spec这个field以及其它详细信息,并且需要是JSON的格式。一般情况下,我们用yaml格式来提供一个对象的声明,kubectl会把这个声明转换成JSON格式,然后传给API Server。
下面是一个Deployment对象的例子:
1 | apiVersion: apps/v1beta1 |
插播一条广告:
Apps
The core workloads API, which is composed of the DaemonSet, Deployment, ReplicaSet, and StatefulSet kinds, has been promoted to GA stability in the apps/v1 group version. As such, the apps/v1beta2 group version is deprecated, and all new code should use the kinds in the apps/v1 group version.
接着说,apiVersion指定了我们调用的api的endpoint;通过kind field,我们指定了我们要创建的对象的类型;通过metadata,我们给对象附加上了最基本的信息,比如名字;你可以发现这里面有两个spec的field(spec和spec.template.spec),通过 spec,我们定义了我们对deployment的期望状态,在我们的例子中,我们想要确认,在任何时候,都有至少3个pod在运行。我们再在spec.template.spec里面定义我们要运行的每个pod都应该是什么状态,所以这就是为啥这里会有两个spec的原因。
一旦这个对象被创建了,kubernetes会直接给对象添加一个status的field,如下:
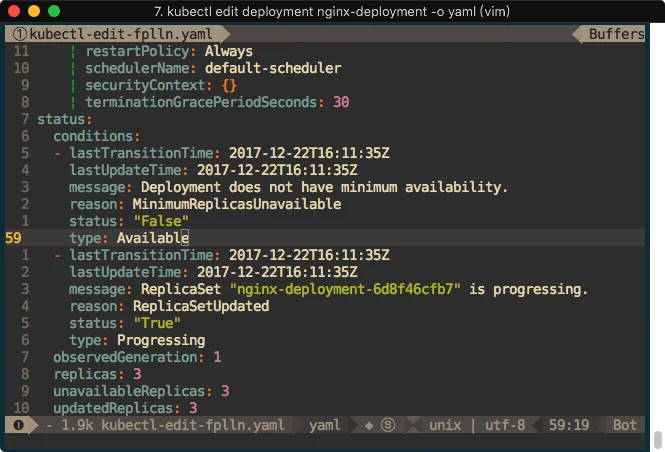
Pods
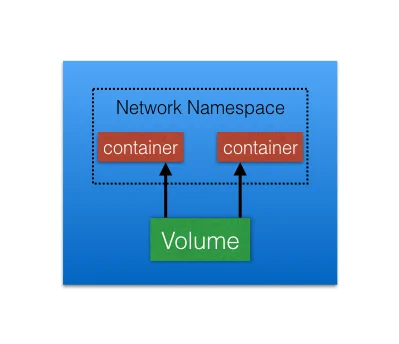
Pod是kubernetes中最简单也是最小的一个对象,是kubernetes部署的一个单元,代表了应用的一个单一实例。一个Pod是一个或者多个容器的逻辑上的集合,这些容器拥有以下的特性:
- 在同一个host上一起进行调度
- 共享同一个network namespace
- 挂载同样的external storage(volumes)
Pod并非一个持久化的东西,很有可能突然挂了,并且没有能力自我修复,这就是为啥我们把它们和controller一起用,这样可以来控制pod的replica,容错,自我修复等等。比较有名的例子比如Deployments,ReplicaSets等。我们通过把Pod的定义(specification,也就是spec)附加到别的对象(也就是之前用的template.spec)来完成。
Labels
Labels都是键值对,这些键值对可以被attach到kubernetes的对象上,比如Pod。Labels一般被用来组织和选择一些符合条件的对象。label不提供唯一性。
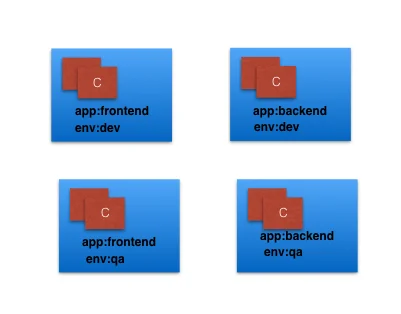
通过这个图片,我们可以看到我们用了两个label:app和env。基于我们的需求,我们可以给我们的pod不同的值。
Label Selectors
通过Label Selectors,我们可以选择一系列的对象,Kubernetes支持两种Selector类型:
Equality-Based Selectors
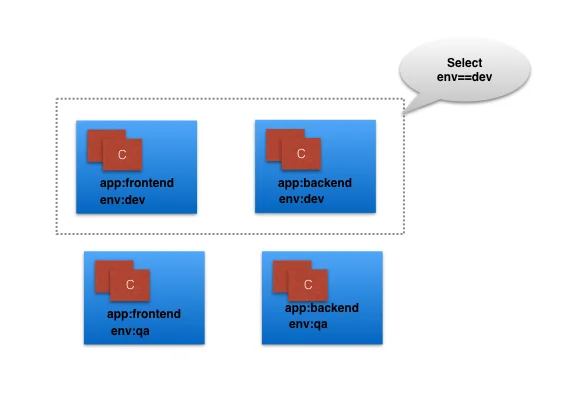
顾名思义,这种selector通过 == 或者 != 来进行选择,比如我们选择一个 env==dev 的对象,就会找出所有有env label,并且值为dev的。
Set-Based Selectors
这种selector支持通过一系列的值来进行过滤,比如通过in, notin和exist。
举例:env in (dev, qa)
Replication Controllers
一个 ReplicationController(rc)是master node上Controller Manager的一部分,主要作用是保证每个pod的replica都达到了预期值。不然的话会通过杀死或者新建pod的办法来达到。不过现在已经被ReplicaSet(rs)取代了。
Replica Sets
Replica Set是下一代的Replication Controller,好处在于同时支持equality 和 set based selector(rc只支持equality-based)。目前这是唯一的区别。
Rs可以单独使用,不过一般是配合deployment一起用。Deployment会自动创建rs来管理下面的pod。
Deployment
deployment提供了对于pod和rs的陈述性更新。DeploymentController是master node上Controller Manager的一部分,作用和Controller manager别的一样——确保当前的状态和期望的状态相同。
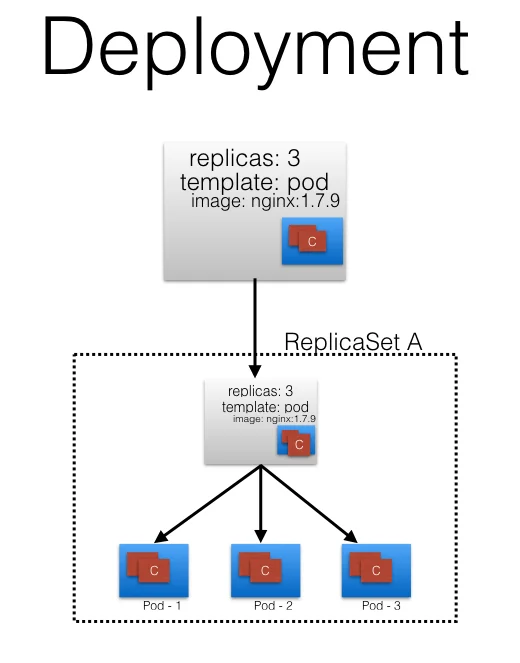
在下面这个例子中,我们的deployment创建了一个 rs A,然后rs A又创建了3个pod,并且在每个pod中,都有一个跑了nginx:1.7.9镜像的容器。
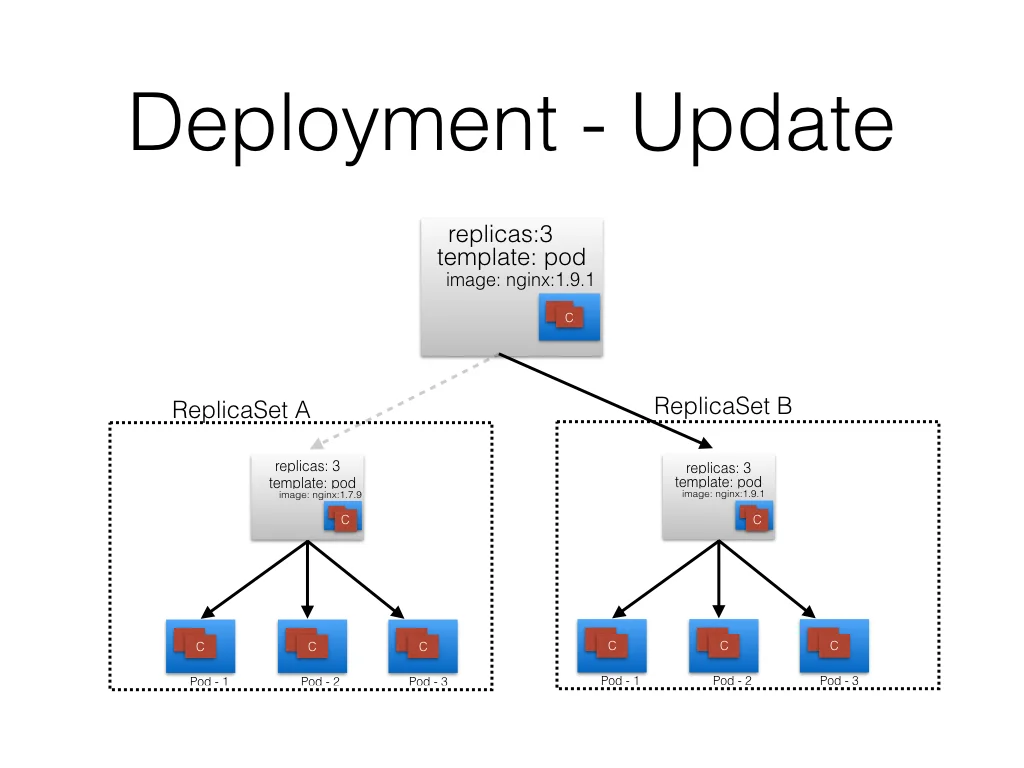
接下来,在下一个deployment中,我们修改了pod的template,把nginx从1.7.9升级到了1.9.1。因为我们升级了期望的状态,所以deployment会创建一个新的rs B,这个过程被称为Deployment rollout:
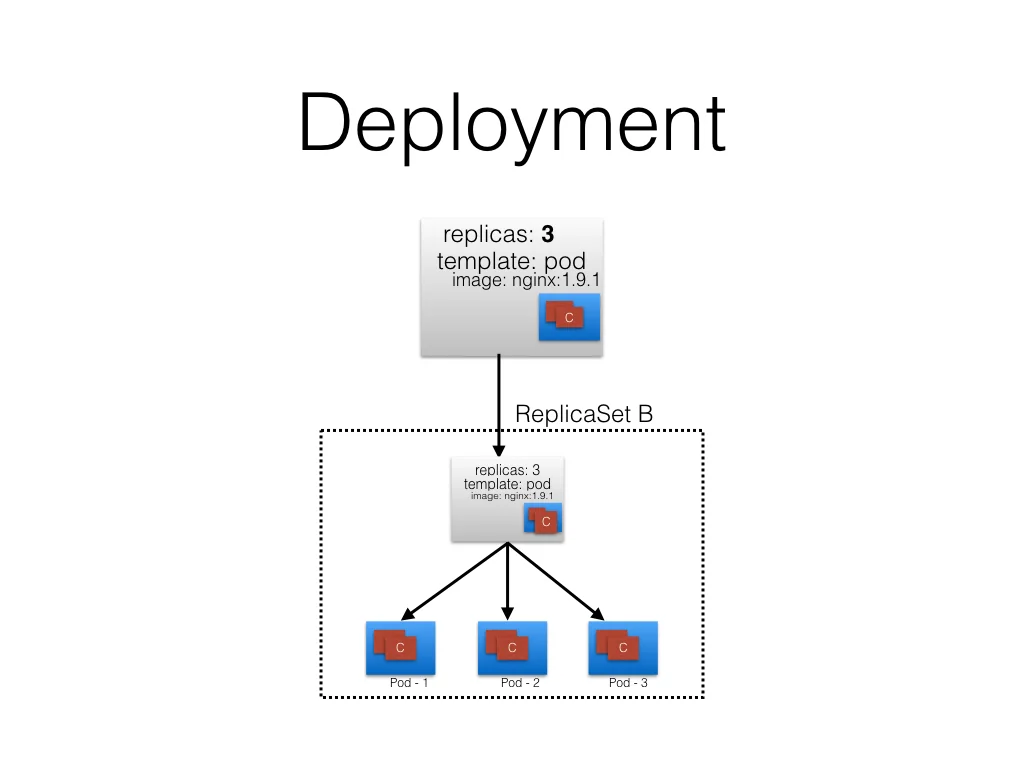
当rs B创建完毕的时候,deployment开始指向它:
在rs之上,deployment提供了很多特性比如recording,通过这个特性,如果说更新出错,或者更新后的应用出了bug,我们可以rollback到原先的状态。
Namespaces
如果我们有无数个用户,我们想把这些用户组织到不同的team或者project,我们可以通过namespace把kubernetes集群分成好多个小集群。所有在namespace中创建的resources/objects都是唯一的,不会跨命名空间。
一般来说,k8s会有两个默认namespace:kube-system和default。kube-system一般会用来放一些kubernetes系统的组件,default会用来放一些属于其它namespace的对象。我们默认情况下是会连接到default命名空间。kube-public是一个特殊的namespace,可以被所有的用户读,一般用于特殊情况比如初始化一个集群。
我们可以通过使用资源配额(Resource Quotas)来限制每个命名空间的资源。
最后再插播一条广告:
