使用人工智能优化 Golang 编译器
有多少人工就有多少智能。 ——鲁迅
缘起
众所周知,字节跳动内部主要使用 Thrift,为了更好地掌控生成代码,我们用 Go 自己实现了 Thrift 代码生成工具。
而我们的故(shi)事(gu),正是由一次重构开始……
在一次平淡无奇的重构发版后,正当我拎着电脑包往外冲心里已经盘算好了回去之后要拿出我熟练度 30W 的至臻 KDA 卡莎大杀四方时,业务方拉住了我,告诉我他们在用了新版的生成代码后,性能下降了10%。
内心 os:What???你们是不是有其它逻辑变更?我写的代码怎么可能有 bug 逻辑一模一样的生成代码怎么可能会有性能差异?
好吧,为了避免突然哪一天账号已停用,我还是耐心地问了业务方一个问题:

于是在一通如此这般地各种标准对齐、环境对齐等等一通操作(此处省略 2^10^10 字)后,我们终于搞清楚了状况:
重构后的生成代码比重构之前,在该业务方的 idl 上,性能真的要差 10%!
What???虽然重构过生成代码,但是新的生成代码无论从语义上还是实现上都是(几乎)和旧的一致的,怎么可能性能会差???
好吧,为了发扬我大 IG 不加班的光辉传统,我们决定直接十五投就完事——把生成代码 revert 回旧版的。好了,问题解决。(第二天,HR:小吴啊,财务室工资结一下)。

正文
先附上我们用来讲解生成代码的 IDL:
1 | struct Example { |
首先,对比一下新旧生成代码(由于代码较多,就不直接贴在文章中了)。
旧代码:https://gist.github.com/PureWhiteWu/bdd28734ab1f675bb7b73ecf0c57e994
新代码:https://gist.github.com/PureWhiteWu/63ac02ee613695213fe9eac4e22493ba
可以看到,新旧生成代码,在编解码逻辑上是完全等价的!不过旧代码采用了局部变量,新代码是直接用的对应结构体的字段。我们怀疑是不是这里的差异导致的(这可能会导致计算 offset 的开销),于是生成了汇编进行比较(由于汇编较大,不直接贴了,有兴趣的同学建议自行生成一下看一下),发现确实是多了一条 MOVQ 语句用来计算偏移量!
1 | MOVQ "".p+144(SP), AX |
看来罪魁祸首好像找到了?不过又感觉哪儿不太对,毕竟现代 CPU 都是有多级流水线的,就多这么一条 MOVQ 语句,对于多级流水线架构的 CPU 来说,性能差距再怎么不可能导致 10% 这么大,特别是尽管这个语句是在 for 循环中的,但是在总的执行的指令占比中也没有 10% 这么多。

为了验证我们的疑问,我们改了一版生成代码,改为了和原先生成的一样使用临时变量,发现确实去掉了这条语句后,性能没有任何变化。也就是说,性能的问题并不是这个间接寻址导致的。
随后,根据生成代码的汇编差异,我们提出了许多猜想,花了大量时间进行验证,但是均不是性能变差的原因(此处过于心酸略过不表)。

最终,我们定位到了是由于在新的生成代码中,相比旧版本的生成代码,在返回错误的时候会额外包装一下:
1 | if err := ...; err != nil { |
而旧版本的生成代码是直接返回的错误:
1 | if err := ...; err != nil { |
虽然这些只是在发生错误的时候才会调用到,在正常流程中不会用到,但是生成的汇编代码中这段逻辑占了相当大的比例:

而 Go 的编译器并没有帮我们重排这些指令,导致在真正运行的时候,L1 cache miss 大大提高,极大地降低了性能,参考如下实验结果:
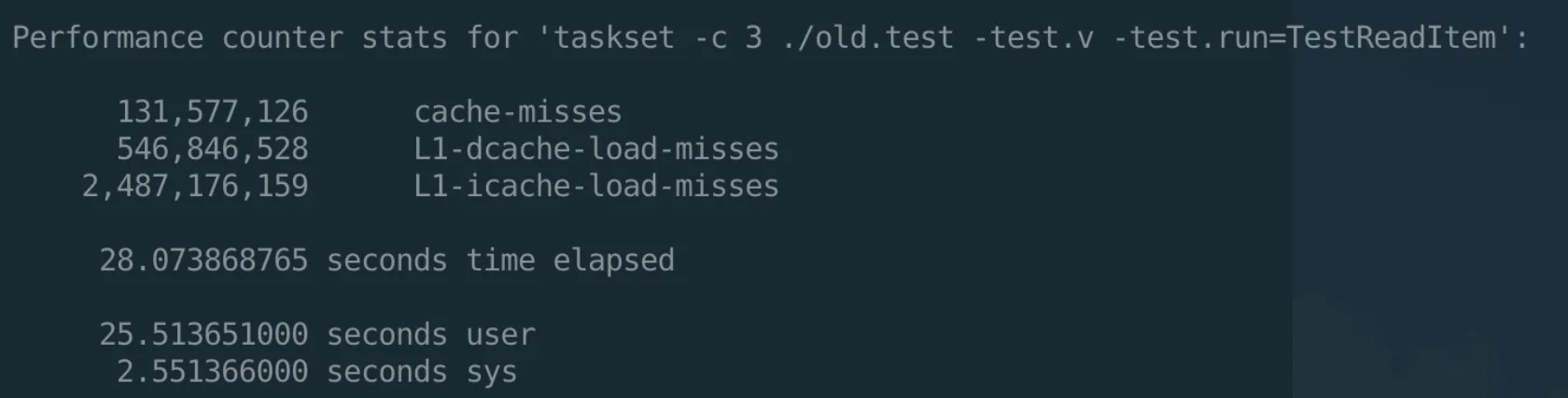
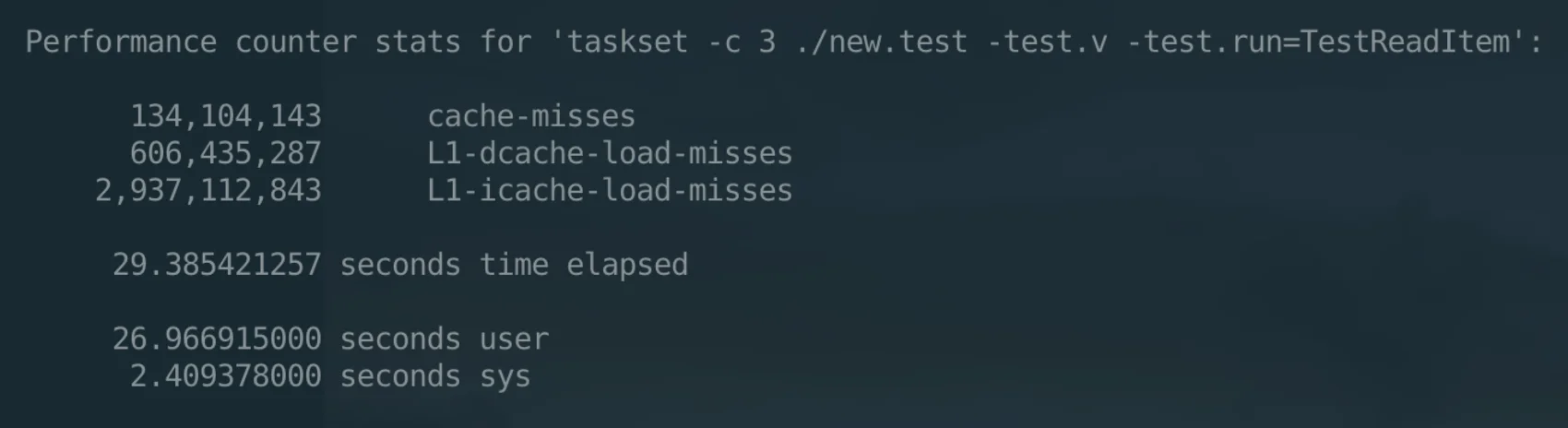
针对这种编译器太弱智导致的问题,只能上人工智能来解决了——有多少人工就有多少智能。

既然编译器不会自动做指令重排,那就我们来帮编译器干这事,改造完成后的生成代码见:https://gist.github.com/PureWhiteWu/296f2bdac6051e4052a68c2bb1de1c07
比较关键的方法是,我们在所有原先return thrift.PrependError的地方,都改为了goto XXXError,如下:
1 | func (p *Example) Read(iprot thrift.TProtocol) error { |
通过这种方式,使得我们正常流程中,如果判断 err 出错的情况之下,不再有之前的一大段处理的指令,而仅仅是变成了一条简单的 jmp 指令;而对应的错误处理逻辑,则尽可能放在正常流程 return 之后,使得尽可能减少 cpu load 指令的次数并降低 L1 icache miss;同时,使得所有的错误处理的逻辑在最终的汇编中只会出现一次,而不是出现多次。
这里必须吐槽一波,Go 编译器有时候会“贴心”地帮你把这些代码挪回到上面,但是由于只会出现一次而其它错误处理的地方都会直接 jmp,所以问题也不大,后续可以考虑试一下把这些逻辑扔到一个独立的函数中并标记 noinline 是否可以再度提高性能(使得在主流程中完全不出现)。
经过这个调整,perf 的性能明显好了很多,并且可能比旧版本更优:
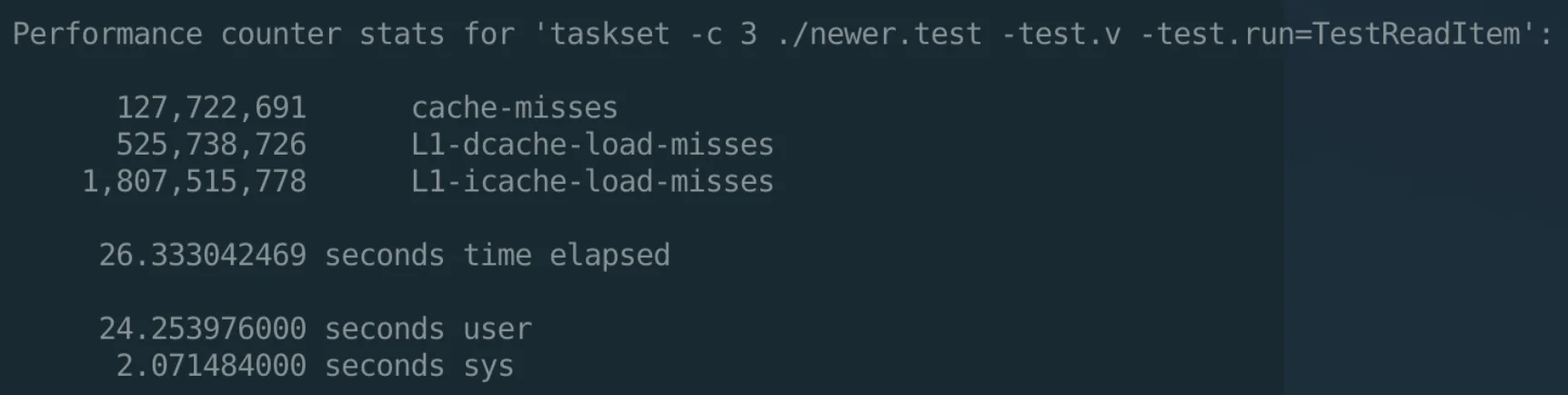
The End
至此,这个问题算是搞明白了,在这个过程中,最大的收获是:Go 编译器竟然如此的弱智 人工指令重排竟然能带来如此之大的提升。
谨以此文分享我们的经验,希望能够抛砖引玉,为性能优化提出一个新的思路,毕竟鲁迅曾说过:
